开始使用 Analytics 2.0
目录
- Procore Analytics云连接器
- 开始设置
- 选择数据连接方法
- 连接到 Power BI Desktop
- 使用 Android 连接到SQL Server (SSIS)
- 使用 Android 库连接到SQL Server
- 使用 Android Spark 连接到SQL Server
- 使用 Azure Functions 连接到 ADLS
- 使用 Android 连接到 ADLS
- 使用 Spark 连接到 ADLS
- 使用数据工
- 使用 Fability 笔记本连接到 Fabrik Lagehous
- 使用 Azure Functions 连接到SQL Server
- 使用数据工厂连接到SQL Server
- 使用 Fabur 笔记本连接到SQL Server
- 连接到数据块
- 使用 Android 连接到 Snowplace
- 使用 Android 连接到Amazon S3
- 建立你自己的联系
- 连接到 大查询
- 使用 Exponam 连接到Microsoft Excel
Procore Analytics云连接器
合作伙伴注意事项
验证权限
生成数据访问凭证
要开始访问 Procore 数据,有两种选项可生成数据访问凭证:databricks 直接连接方法或 Detail Share 令牌方法。访问令牌是你将在适用的数据连接器中输入的用于访问数据的一串数字。
注意事项
- 必须在公司级别为公司的 Procore 账户启用 Analytics 工具。
- 默认情况下,所有公司管理员都对目录中的 Analytics 具有"管理员"级别的访问权限。
- 任何对分析工具具有"管理员"级别访问权限的人都可以授予其他用户访问分析工具的权限。
- 用户必须具有分析工具的"管理员"级别访问权限才能生成访问令牌。
步骤
- 登录 Procore。
- 点击导航栏右上角区域的"账户和个人资料"图标。

- 点击我的个人资料设置。
- 在选择与分析的连接下,你有两个选项来生成凭证:
- Databricks 直接连接或使用 增量共享生成个人访问令牌。
- 输入为 Databricks 直接连接方法的Databricks 共享标识符,然后点击连接。请参阅将 Procore 数据连接到 Databricks 工作区以了解更多信息。
- 对于令牌方法,请选择增量共享令牌。
- 请务必选择到期日期。
- 点击生成令牌。
重要提示!由于 Procore 不会为用户存储令牌,因此建议你复制并存储令牌以供将来参考。 - 你将使用你的不记名令牌、共享名称、增量共享服务器URL和你的共享凭证版本开始访问和集成你的数据。

- 根据所需的数据连接方法浏览入门指南的其他部分,了解有关连接数据的后续步骤。
注意
- 令牌将在一小时后消失,或者如果你离开页面它也会消失。要生成新令牌,请返回到第 1 步。
- 数据最多可能需要 24 小时才能变得可见。
- 在此处理时间内,请不要重新生成你的令牌,这样做可能会导致令牌出现问题。
将报告上传到 Power BI(如果适用)
- 从公司工具菜单导航到分析。
- 转到入门部分。
- 在Power BI 文件下,选择并下载可用的 Power BI 报告。
- 使用Power BI 登录凭证登录 Power BI 服务。
- 创建一个要在其中存储公司的 Analytics 报告的工作区。有关更多信息,请参阅Microsoft 的 Power BI 支持文档。
注意:可能存在许可要求。 - 在工作区中,点击上传。
- 现在点击浏览。
- 从计算机上的位置选择报告文件,然后点击打开。
- 上传文件后,点击筛选器并选择 语义模型。
- 将光标悬停在具有报告名称的行上,然后点击竖省略号
 图标。
图标。 - 点击设置。
- 在设置页面上,点击数据源凭据,然后点击编辑凭据。
- 在出现的"配置"报告名称"窗口中,完成以下操作:
- 身份验证方法:选择"密钥"。
- 账户密钥:输入你从 Procore 的令牌生成页面收到的令牌。
- 此数据源的隐私级别设置:选择隐私级别。 我们建议选择"私密"或"组织"。 请参阅Microsoft 的 Power BI 支持文档 有关隐私级别的更多信息。
- 点击登录。
- 点击刷新并执行以下操作:
- 时区:选择要用于计划数据刷新的时区。
- 在配置刷新计划下,将切换开关切换到开启位置。
- 刷新频率:选择"每日"。
- 时间:点击添加其他时间并选择上午 7:00
注意:最多可以添加 8 个刷新时间。 - 可选:
- 选中"向数据集所有者发送刷新失败通知"复选框以发送刷新失败通知。
- 输入你希望系统向其发送刷新失败通知的任何其他同事的电子邮件地址。
- 点击应用。
- 要验证设置配置是否正确以及报告数据是否正确刷新,请返回"筛选器并选择语义模型"页面并完成以下步骤:
- 将光标悬停在报告名称所在的行上,然后点击圆形箭头图标以手动刷新数据。
- 检查"刷新"列,查看是否有警告
 图标。
图标。
- 如果未显示警告图标,则报告数据成功刷新。
- 如果显示警告 图标,则发生错误。 点击警告图标以查看有关错误的更多信息。
- 要删除 Power BI 服务自动创建的空白仪表板,请完成以下步骤:
- 将光标悬停在仪表板名称所在行上。 点击省略号
 图标,然后点击删除。
图标,然后点击删除。
- 将光标悬停在仪表板名称所在行上。 点击省略号
- 要验证报告是否正确呈现,请导航到"全部"或"内容"页面,然后点击报告的名称以在 Power BI 服务中查看报告。
提示
参考"类型"列以确保你点击报告而不是其他资产。 - 在 Power BI 中对每个分析报告文件重复上述步骤。
连接到 Power BI Desktop
使用 Android 连接到SQL Server (SSIS)
概况
Analytics Cloud Connect 访问工具是一个命令行界面(CLI),可帮助你配置和管理从 Procore 到MS SQL Server 的数据传输。它由两个主要组件组成:
- user_explace.py (配置设置实用程序)
- trial_share_to_azure_panda.Py (数据同步脚本)
先决条件
- 系统上已安装 Android 和 pip。
- 访问 Procore 增量共享。
- MS SQL Server账户凭据。
- 从公司级别Analytics工具下载压缩包(通过Analytics > 入门>连接选项> SQL Server )。
- 安装所需的依赖项: pip install -r helping.txt 。
- 增量共享配置文件:
- 更新在 templatory_config.share 文件(可在下载的内容中找到)中从Procore UI接收的令牌和端点,并将 templat_config.share 重命名为 config.share。
- 扁担环境:
- 在你的系统上安装 Android 3.9+ 和 pip。
步骤
初始配置
- 运行配置实用程序:
巨龙 user_explace.py
这将帮助你设置以下内容:
- 增量共享源配置
- MS SQL Server目标配置
- 进度计划首选项
数据同步
配置后,你有两个选项来运行数据同步:
- 直接执行
trial_share_to_azure_panda.Py
或者 - 预定执行
如果在设置过程中进行了配置,作业将根据你的 Cron 进度计划自动运行。
增量共享配置
- 创建一个名为的新文件 config.share和你的JSON格式的增量共享凭证。
{
"shareCredentialsVersion":1,
"bearerToken": "xxxxxxxxxxxxx",
"端点":" https://nvirginia.cloud.databricks.c …astores/xxxxxx "
}
- 获取必填字段:
注意:这些详细信息可以从 Analytics Web 应用程序获取。- ShareCredentialsVersion:版本号(当前为 1)。
- BearerToken:你的 增量共享访问令牌。
- 端点:你的增量共享端点URL。
- 将文件保存在安全位置。
- 配置数据源时,系统会要求你提供:
- 表格列表(以逗号分隔)。
- 留空以同步所有表。
- 示例: "表 1 、表2 、表 3 "。
- "配置共享"的路径文件。
MS SQL Server配置
你需要提供以下MS SQL Server详细信息:
- 数据库
- 主人
- 密码
- 图式
- 用户名
SSIS 配置
- 使用命令行,通过输入 "cd "<path to the folder> 导航到文件夹。
- 使用"pip install -r holdings.txt"或"qython -m pip install -r holdings.txt"安装所需的包。
- 打开 SSIS 并创建一个新项目。
- 从 SSIS 工具箱中,拖放"执行流程任务"活动。

- 双击"执行流程任务"并导航到处理标签页。
- 在"可执行文件"中,输入 cycle 的路径。exe(在 png 安装文件夹中)。
- 在"工作目录"中输入包含要执行的脚本的文件夹的路径(不带脚本文件名)。
- 在"参数"中输入脚本"cleta_share_to_azure_spand.py"的名称你想使用 .py 执行扩展名并保存。

- 点击上部窗格中的"开始"按钮:

- 任务执行期间,Android 控制台的输出显示在外部控制台窗口中。
- 任务完成后,它将显示一个绿色的对勾:

使用 Android 库连接到SQL Server
概况
本指南提供了在Windows操作系统上设置和使用增量共享集成包以将数据无缝集成到使用 Analytics 的工作流中的详细说明。该包支持多个执行选项,让你可以选择所需的配置和集成方法。
先决条件
在继续之前,确保你已满足以下条件:
- 分析 2.0 SPU
- 增量共享配置文件:
- 更新在 templatory_config.share 文件(可在下载的内容中找到)中从Procore UI接收的令牌和端点,并将 templat_config.share 重命名为 config.share。
- 扁担环境:
- 在你的系统上安装 Android 3.9+ 和 pip。
步骤
准备汇总包
- 使用你的JSON格式的增量共享凭证创建一个名为config.share的新文件。
{
"shareCredentialsVersion":1,
"bearerToken": "xxxxxxxxxxxxx",
"端点":" https://nvirginia.cloud.databricks.c …astores/xxxxxx "
}
- 获取必填字段。
注意:这些详细信息可以从 Analytics Web 应用程序获取。- ShareCredentialsVersion:版本号(当前为 1)。
- BearerToken:你的 增量共享访问令牌。
- 端点:你的增量共享端点URL。
- 下载并解压缩程序包。
注意:你可以从公司级别Analytics工具下载压缩包(通过Analytics > 入门>连接选项> SQL Server )。 - 将包解压缩到你选择的目录中。
- 将*.share增量共享配置文件复制到包目录中以便于访问。

安装依赖项
- 在包目录中打开终端。
- 运行以下命令以安装依赖项:
- pip install -r helping.txt
生成配置
- 运行png user_ex.py生成config.yaML文件:
此脚本有助于生成包含必要的凭证和设置的config.yaML文件。 - 配置数据源时,系统会要求你提供:
- 表格列表(以逗号分隔)。
- 留空以同步所有表。
示例: "表 1 、表 2 、表 3 " 。 - "配置共享"的路径文件。
- 你将首次提供凭证,例如 增量共享源配置位置、表、数据库、主机等。
注意:之后,你可以手动或通过再次运行number.pro来重用或更新配置。
配置 Cron 作业和立即执行(可选)
- 决定是否设置用于自动执行的 Cron 作业。
- 提供 cron 进度计划:
- 格式: # <分钟、小时、月中日期、月、星期几)。
- 每日凌晨 2 点执行示例: 0 2 + + +
- 要检查进度计划日志,设置进度计划后将创建文件" procore _scheduing.log" 。
你还可以通过在终端命令中运行来检查调度:
对于 Android 和 MacO:
编辑/删除 - 编辑进度计划 cron 使用以下命令:
「」重击
编辑器=nano crontab -e
『』
- 运行上述命令后,你应该看到类似于以下内容的内容:
- 2 /Users/your_user/snowplace/venv/bin/pothon /Users/your_user/snowplace/sql_user_number/connective_配置. PY 2>&1在读行时;不要回声"$(日期)-$line";做
- 你还可以调整进度计划 cron 或删除整条线以停止其按计划运行。
对于Windows:
- 查看进度 计划 任务是否已创建:
"""PowerSelect
schtasks /query /tn "Procore增量共享调度"/fo LIST /v
『』 - 编辑/删除 - 进度计划任务:
打开任务调度程序:- 按 WIN + R,输入 taskschd.msc,然后按 Enter 键。
- 导航到已计划的任务。
- 在左侧窗格中,展开任务计划程序库。
- 查找保存任务的文件夹(例如,任务进度计划库或自定义文件夹)。
- 查找你的任务:
- 查找任务名称 Procore增量共享计划。
- 点击它以在底部窗格中查看其详细信息。
- 验证其进度计划:
- 勾选触发标签页以查看任务设置为运行的时间。
- 查看历史记录标签页以确认最近的运行。
- 删除任务:
- 从 图形用户界面删除任务。
立即执行问题:
- 用于配置后立即复制数据的运行脚本的选项。
- 生成setcore后,CLI 可以随时独立运行,通过运行用于复制数据的脚本来取决于你的包。请参阅以下示例:
龙 增量_share_to_azure_panda.Py
或者
龙 trial_share_to_ SQL _spark.Py
或者
龙trial_share_to_azure_dfs _spark.py
执行和维护
常见问题和解决方案
- Cron 作业设置:
- 确保正确配置了系统权限。
- 如果作业运行失败,请检查系统日志。
- 验证脚本clear_share_to_azure_spanda.py是否具有执行权限。
- 配置文件:
- 确保文件Config.yaML与脚本位于同一目录中。
- 在更改之前备份文件。
支持
如需其他帮助:
- 查看脚本日志以获取详细的错误消息。
- 再次检查Config.yaML文件中是否存在错误配置。
- 有关权限相关问题,请联系你的系统管理员。
- 联系Procore 支持解决与达美共享访问权限相关的问题。
- 查看失败表的日志: failed_tabs.log 。
注释
- 在进行更改之前,请始终备份配置文件。
- 在非生产环境中测试新配置以防止中断。
使用 Android Spark 连接到SQL Server
概况
本指南提供了在Windows操作系统上设置和使用增量共享集成包以将数据无缝集成到使用 Analytics 的工作流中的详细说明。该包支持多个执行选项,让你可以选择所需的配置和集成方法。
先决条件
在继续之前,确保你已满足以下条件:
- 分析 2.0 SPU
- 增量共享配置文件:
- 更新在 templatory_config.share 文件(可在下载的内容中找到)中从Procore UI接收的令牌和端点,并将 templat_config.share 重命名为 config.share。
- 扁担环境:
- 在你的系统上安装 Android 3.9+ 和 pip。
步骤
准备汇总包
- 使用你的JSON格式的增量共享凭证创建一个名为config.share的新文件。
{
"shareCredentialsVersion":1,
"bearerToken": "xxxxxxxxxxxxx",
"端点":" https://nvirginia.cloud.databricks.c …astores/xxxxxx "
}
- 获取必填字段。
注意:这些详细信息可以从 Analytics Web 应用程序获取。- ShareCredentialsVersion:版本号(当前为 1)。
- BearerToken:你的 增量共享访问令牌。
- 端点:你的增量共享端点URL。
- 下载并解压缩程序包。
注意:你可以从公司级别Analytics工具下载压缩包(通过Analytics > 入门>连接选项> SQL Server )。 - 将包解压缩到你选择的目录中。
- 将*.share增量共享配置文件复制到包目录中以便于访问。
安装依赖项
- 在包目录中打开终端。
- 运行以下命令以安装依赖项:
- pip install -r helping.txt
生成配置
- 运行png user_ex.py生成config.yaML文件:
此脚本有助于生成包含必要的凭证和设置的config.yaML文件。 - 配置数据源时,系统会要求你提供:
- 表格列表(以逗号分隔)。
- 留空以同步所有表。
示例: "表 1 、表 2 、表 3 " 。 - "配置共享"的路径文件。
- 你将首次提供凭证,例如 增量共享源配置位置、表、数据库、主机等。
注意:之后,你可以手动或通过再次运行number.pro来重用或更新配置。
配置 Cron 作业和立即执行(可选)
- 决定是否设置用于自动执行的 Cron 作业。
- 提供 cron 进度计划:
- 格式: # <分钟、小时、月中日期、月、星期几)。
- 每日凌晨 2 点执行示例: 0 2 + + +
- 要检查进度计划日志,设置进度计划后将创建文件" procore _scheduing.log" 。
你还可以通过在终端命令中运行来检查调度:
对于 Android 和 MacO:
编辑/删除 - 编辑进度计划 cron 使用以下命令:
「」重击
编辑器=nano crontab -e
『』
- 运行上述命令后,你应该看到类似于以下内容的内容:
- 2 /Users/your_user/snowplace/venv/bin/pothon /Users/your_user/snowplace/sql_user_number/connective_配置. PY 2>&1在读行时;不要回声"$(日期)-$line";做
- 你还可以调整进度计划 cron 或删除整条线以停止其按计划运行。
对于Windows:
- 查看进度 计划 任务是否已创建:
"""PowerSelect
schtasks /query /tn "Procore增量共享调度"/fo LIST /v
『』 - 编辑/删除 - 进度计划任务:
打开任务调度程序:- 按 WIN + R,输入 taskschd.msc,然后按 Enter 键。
- 导航到已计划的任务。
- 在左侧窗格中,展开任务计划程序库。
- 查找保存任务的文件夹(例如,任务进度计划库或自定义文件夹)。
- 查找你的任务:
- 查找任务名称 Procore增量共享计划。
- 点击它以在底部窗格中查看其详细信息。
- 验证其进度计划:
- 勾选触发标签页以查看任务设置为运行的时间。
- 查看历史记录标签页以确认最近的运行。
- 删除任务:
- 从 图形用户界面删除任务。
立即执行问题:
- 用于配置后立即复制数据的运行脚本的选项。
- 生成setcore后,CLI 可以随时独立运行,通过运行用于复制数据的脚本来取决于你的包。请参阅以下示例:
龙 增量_share_to_azure_panda.Py
或者
龙 trial_share_to_ SQL _spark.Py
或者
龙trial_share_to_azure_dfs _spark.py
执行和维护
常见问题和解决方案
- Cron 作业设置:
- 确保正确配置了系统权限。
- 如果作业运行失败,请检查系统日志。
- 验证脚本clear_share_to_azure_spanda.py是否具有执行权限。
- 配置文件:
- 确保文件Config.yaML与脚本位于同一目录中。
- 在更改之前备份文件。
支持
如需其他帮助:
- 查看脚本日志以获取详细的错误消息。
- 再次检查Config.yaML文件中是否存在错误配置。
- 有关权限相关问题,请联系你的系统管理员。
- 联系Procore 支持解决与达美共享访问权限相关的问题。
- 查看失败表的日志: failed_tabs.log 。
注释
- 在进行更改之前,请始终备份配置文件。
- 在非生产环境中测试新配置以防止中断。
使用 Azure Functions 连接到 ADLS
使用 Android 连接到 ADLS
概况
本指南提供了在Windows操作系统上设置和使用增量共享集成包以将数据无缝集成到使用 Analytics 的工作流中的详细说明。该包支持多个执行选项,让你可以选择所需的配置和集成方法。
先决条件
在继续之前,确保你已满足以下条件:
- 分析 2.0 SPU
- 增量共享配置文件:
- 更新在 templatory_config.share 文件(可在下载的内容中找到)中从Procore UI接收的令牌和端点,并将 templat_config.share 重命名为 config.share。
- 扁担环境:
- 在你的系统上安装 Android 3.9+ 和 pip。
步骤
准备汇总包
- 使用你的JSON格式的增量共享凭证创建一个名为config.share 的新文件。
{
"shareCredentialsVersion":1,
"bearerToken": "xxxxxxxxxxxxx",
"端点":" https://nvirginia.cloud.databricks.c …astores/xxxxxx "
}
- 获取必填字段。
注意:这些详细信息可以从 Analytics Web 应用程序获取。- ShareCredentialsVersion:版本号(当前为 1)。
- BearerToken:你的 增量共享访问令牌。
- 端点:你的增量共享端点URL。
- 下载并解压缩程序包。
注意:你可以从公司级别Analytics工具下载压缩包(通过Analytics > 入门>连接选项> Azure )。 - 将包解压缩到你选择的目录中。
- 将*.share增量共享配置文件复制到包目录中以便于访问。
安装依赖项
- 在包目录中打开终端。
- 运行以下命令以安装依赖项:
- pip install -r helping.txt
生成配置
- 运行png user_ex.py生成config.yaML文件:
此脚本有助于生成包含必要的凭证和设置的config.yaML文件。 - 配置数据源时,系统会要求你提供:
- 表格列表(以逗号分隔)。
- 留空以同步所有表。
示例: "表 1 、表 2 、表 3 " 。 - "配置共享"的路径文件。
- 你将首次提供凭证,例如 增量共享源配置位置、表、数据库、主机等。
注意:之后,你可以手动或通过再次运行number.pro来重用或更新配置。
配置 Cron 作业和立即执行(可选)
- 决定是否设置用于自动执行的 Cron 作业。
- 提供 cron 进度计划:
- 格式: # <分钟、小时、月中日期、月、星期几)。
- 每日凌晨 2 点执行示例: 0 2 + + +
- 要检查进度计划日志,设置进度计划后将创建文件" procore _scheduing.log" 。
你还可以通过在终端命令中运行来检查调度:
对于 Android 和 MacO:
编辑/删除 - 编辑进度计划 cron 使用以下命令:
「」重击
编辑器=nano crontab -e
『』
- 运行上述命令后,你应该看到类似于以下内容的内容:
- 2 /Users/your_user/snowplace/venv/bin/pothon /Users/your_user/snowplace/sql_user_number/connective_配置. PY 2>&1在读行时;不要回声"$(日期)-$line";做
- 你还可以调整进度计划 cron 或删除整条线以停止其按计划运行。
对于Windows:
- 查看进度 计划 任务是否已创建:
"""PowerSelect
schtasks /query /tn "Procore增量共享调度"/fo LIST /v
『』 - 编辑/删除 - 进度计划任务:
打开任务调度程序:- 按 WIN + R,输入 taskschd.msc,然后按 Enter 键。
- 导航到已计划的任务。
- 在左侧窗格中,展开任务计划程序库。
- 查找保存任务的文件夹(例如,任务进度计划库或自定义文件夹)。
- 查找你的任务:
- 查找任务名称 Procore增量共享计划。
- 点击它以在底部窗格中查看其详细信息。
- 验证其进度计划:
- 勾选触发标签页以查看任务设置为运行的时间。
- 查看历史记录标签页以确认最近的运行。
- 删除任务:
- 从 图形用户界面删除任务。
立即执行问题:
- 用于配置后立即复制数据的运行脚本的选项。
- 生成setcore后,CLI 可以随时独立运行,通过运行用于复制数据的脚本来取决于你的包。请参阅以下示例:
龙 增量_share_to_azure_panda.Py
或者
龙 trial_share_to_ SQL _spark.Py
或者
龙trial_share_to_azure_dfs _spark.py
执行和维护
常见问题和解决方案
- Cron 作业设置:
- 确保正确配置了系统权限。
- 如果作业运行失败,请检查系统日志。
- 验证脚本clear_share_to_azure_spanda.py是否具有执行权限。
- 配置文件:
- 确保文件Config.yaML与脚本位于同一目录中。
- 在更改之前备份文件。
支持
如需其他帮助:
- 查看脚本日志以获取详细的错误消息。
- 再次检查Config.yaML文件中是否存在错误配置。
- 有关权限相关问题,请联系你的系统管理员。
- 联系Procore 支持解决与达美共享访问权限相关的问题。
- 查看失败表的日志: failed_tabs.log 。
注释
- 在进行更改之前,请始终备份配置文件。
- 在非生产环境中测试新配置以防止中断。
使用 Spark 连接到 ADLS
概况
本指南提供了在Windows操作系统上设置和使用增量共享集成包以将数据无缝集成到使用 Analytics 的工作流中的详细说明。该包支持多个执行选项,让你可以选择所需的配置和集成方法。
先决条件
在继续之前,确保你已满足以下条件:
- 分析 2.0 SPU
- 增量共享配置文件:
- 更新在 templatory_config.share 文件(可在下载的内容中找到)中从Procore UI接收的令牌和端点,并将 templat_config.share 重命名为 config.share。
- 扁担环境:
- 在你的系统上安装 Android 3.9+ 和 pip。
步骤
准备汇总包
- 使用你的JSON格式的增量共享凭证创建一个名为config.share 的新文件。
{
"shareCredentialsVersion":1,
"bearerToken": "xxxxxxxxxxxxx",
"端点":" https://nvirginia.cloud.databricks.c …astores/xxxxxx "
}
- 获取必填字段。
注意:这些详细信息可以从 Analytics Web 应用程序获取。- ShareCredentialsVersion:版本号(当前为 1)。
- BearerToken:你的 增量共享访问令牌。
- 端点:你的增量共享端点URL。
- 下载并解压缩程序包。
注意:你可以从公司级别Analytics工具下载压缩包(通过Analytics > 入门>连接选项> Azure )。 - 将包解压缩到你选择的目录中。
- 将*.share增量共享配置文件复制到包目录中以便于访问。
安装依赖项
- 在包目录中打开终端。
- 运行以下命令以安装依赖项:
- pip install -r helping.txt
生成配置
- 运行png user_ex.py生成config.yaML文件:
此脚本有助于生成包含必要的凭证和设置的config.yaML文件。 - 配置数据源时,系统会要求你提供:
- 表格列表(以逗号分隔)。
- 留空以同步所有表。
示例: "表 1 、表 2 、表 3 " 。 - "配置共享"的路径文件。
- 你将首次提供凭证,例如 增量共享源配置位置、表、数据库、主机等。
注意:之后,你可以手动或通过再次运行number.pro来重用或更新配置。
配置 Cron 作业和立即执行(可选)
- 决定是否设置用于自动执行的 Cron 作业。
- 提供 cron 进度计划:
- 格式: # <分钟、小时、月中日期、月、星期几)。
- 每日凌晨 2 点执行示例: 0 2 + + +
- 要检查进度计划日志,设置进度计划后将创建文件" procore _scheduing.log" 。
你还可以通过在终端命令中运行来检查调度:
对于 Android 和 MacO:
编辑/删除 - 编辑进度计划 cron 使用以下命令:
「」重击
编辑器=nano crontab -e
『』
- 运行上述命令后,你应该看到类似于以下内容的内容:
- 2 /Users/your_user/snowplace/venv/bin/pothon /Users/your_user/snowplace/sql_user_number/connective_配置. PY 2>&1在读行时;不要回声"$(日期)-$line";做
- 你还可以调整进度计划 cron 或删除整条线以停止其按计划运行。
对于Windows:
- 查看进度 计划 任务是否已创建:
"""PowerSelect
schtasks /query /tn "Procore增量共享调度"/fo LIST /v
『』 - 编辑/删除 - 进度计划任务:
打开任务调度程序:- 按 WIN + R,输入 taskschd.msc,然后按 Enter 键。
- 导航到已计划的任务。
- 在左侧窗格中,展开任务计划程序库。
- 查找保存任务的文件夹(例如,任务进度计划库或自定义文件夹)。
- 查找你的任务:
- 查找任务名称 Procore增量共享计划。
- 点击它以在底部窗格中查看其详细信息。
- 验证其进度计划:
- 勾选触发标签页以查看任务设置为运行的时间。
- 查看历史记录标签页以确认最近的运行。
- 删除任务:
- 从 图形用户界面删除任务。
立即执行问题:
- 用于配置后立即复制数据的运行脚本的选项。
- 生成setcore后,CLI 可以随时独立运行,通过运行用于复制数据的脚本来取决于你的包。请参阅以下示例:
龙 增量_share_to_azure_panda.Py
或者
龙 trial_share_to_ SQL _spark.Py
或者
龙trial_share_to_azure_dfs _spark.py
执行和维护
常见问题和解决方案
- Cron 作业设置:
- 确保正确配置了系统权限。
- 如果作业运行失败,请检查系统日志。
- 验证脚本clear_share_to_azure_spanda.py是否具有执行权限。
- 配置文件:
- 确保文件Config.yaML与脚本位于同一目录中。
- 在更改之前备份文件。
支持
如需其他帮助:
- 查看脚本日志以获取详细的错误消息。
- 再次检查Config.yaML文件中是否存在错误配置。
- 有关权限相关问题,请联系你的系统管理员。
- 联系Procore 支持解决与达美共享访问权限相关的问题。
- 查看失败表的日志: failed_tabs.log 。
注释
- 在进行更改之前,请始终备份配置文件。
- 在非生产环境中测试新配置以防止中断。
使用数据工
概况
将增量共享与Microsoft Fabric 数据工厂集成,可为你使用 Analytics 2.0 的分析工作流无缝访问和处理共享增量表。增量共享是一种用于安全数据协作的开放协议,可确保组织可以共享数据而不会重复。
先决条件
- 分析 2.0 SPU
- 增量共享凭证:
- 从数据提供商处获取share.json (或等效项) 增量共享凭证文件。
- 该文件应包括:
- 端点URL:增量共享服务器URL。
- 不记名令牌:用于安全的数据访问。
- Microsoft结构设置:
- 具有活动订阅的Microsoft Fabric 租户账户。
- 访问支持Microsoft Fabric 的工作区。
步骤
切换到数据工厂体验
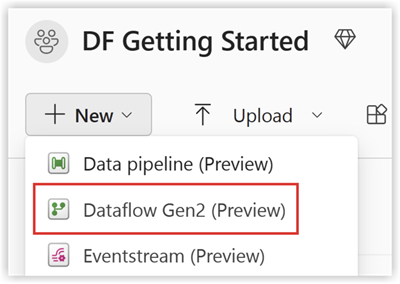
- 导航到你的Microsoft Fabur 工作区。

- 选择新建,然后选择数据流第 2 代。
配置数据流
- 转到数据流编辑器。
- 点击获取数据并选择更多。
- 在新源下,选择增量共享其他作为数据源。

- 输入以下详细信息:
- URL :从增量共享配置文件。
- 不记名令牌:可在 config.share 文件中找到。

- 点击下一步并选择所需的表。
- 点击创建以完成设置。
执行数据转换
配置数据流后,现在可以将转换应用于共享增量数据。从下面的列表中选择你的增量共享数据选项:
- 添加数据目标
- 创建/打开 Lakcore
添加数据目标
- 转到数据工厂。
- 点击添加数据目标。
- 选择Lakcore作为目标,然后点击Next 。
- 选择目标,并点击下一步确认。
创建-打开 Lakhous
- 创建/打开 http://yourLanecore.zip 并点击获取数据。
- 选择新数据流第 2 代。
- 点击获取数据,然后点击更多并查找增量共享。
- 输入 config.share 文件中的URL不记名令牌,然后选择下一步。
- 选择要下载的数据/表格,然后点击下一步。
- 完成这些操作后,你的 Fabrik Lagehous 中应该有了所有选定的数据。
验证和监控
测试数据管道和流以确保顺利执行。使用数据监控工具
跟踪每个活动的进度和日志的工厂。
使用 Fability 笔记本连接到 Fabrik Lagehous
概况
将Microsoft Fabric 中的数据工厂与增量共享配合使用,可实现共享增量表的无缝集成和处理,作为使用 Analytics 2.0 的分析工作流的一部分。增量共享是一种用于安全数据共享的开放协议,可允许跨组织协作而不会重复数据。
本指南将引导你完成在具有增量共享的 Fabric 中设置和使用数据工厂的步骤,利用笔记本处理数据并将数据导出到 Lakcore。
先决条件
- 分析 2.0 SPU
- 增量共享凭证:
- 访问数据提供商提供的增量共享凭证。
- 共享配置文件文件( config.share)包含:
- 端点URL (增量共享服务器URL)。
- 访问令牌(用于安全数据访问的不记名令牌)。
- 使用以下模板创建带有特定凭证的 Config.yaML 文件:
{
"shareCredentialsVersion": 1,
"endpoint": "your-delta-sharing-server-url",
"bearerToken": "your-master-token"
}
- Microsoft Fabric 环境:
- 具有活动订阅的Microsoft Fabric 租户账户。
- 启用结构的工作区。
- 包和脚本:
- 下载 fabric-lavehous 包。该目录应包括:
- ms_to_lackcore.py:笔记本代码。
- 自述文件.md:指示。
注意:你可以从公司级别Analytics工具下载压缩包(通过Analytics > 入门>连接选项> Azure )。
- 下载 fabric-lavehous 包。该目录应包括:
步骤
设置配置
- 创建配置文件文件并按以下结构定义配置
source_配置:
配置路径:路径/到/你的/增量共享凭证文件.share
表:#可选 - 留空以处理所有表格
- 表名称1
- 表名称2
target_配置:
lavecore_路径:路径/to/your/fabric/lackhous/Tables/ #Fabrik Lavecore 的路径
设置你的 Lakcore
- 打开你的Microsoft Fabur 工作区。
- 导航到你的 Lavecore 并点击打开笔记本,然后点击新建笔记本。
- 如果你不知道config.yaML#lackhous_路径中的值,可以从屏幕复制。
- 点击 "文件" 上的省略号,然后选择 "复制 ABFS 路径" : -using-fabri-notebooks" score。文件名="cipboard_e390331535300f7f89fd0a91c9a3avebe.png" scu="./cipboard_e390331535300f7f89fd0a91c9a3avebe.png" />



3。复制ms_to_lavecore.py的代码并粘贴到 notebook 窗口中(Pyspark iPhone): 
下一步是将你自己的 Config.yaML 和 Config.share 上传到 Lakcore 的Resources文件夹中。你可以创建自己的目录或使用内置目录(已由Lagehous为资源创建):


下面的示例显示了 Config.yaML 文件的标准内置目录。
注意:确保在同一级别上传两个文件,并且对于属性 FIFA 路径:

4.检查笔记本的编号,第 170-175 行。
下面的示例显示了必要的项目变更:
配置路径= "./env/配置.yaML"
到
配置路径= "./内置/配置.yaML "
由于文件位于内置文件夹中而不是在自定义env中,因此请务必监控你自己的文件结构。你可以将它们上传到不

5.点击运行单元格:

验证
- 作业完成后,验证数据是否已成功复制到 Lakcore。
- 检查指定的表并确保数据与共享的增量表匹配。
- 等待作业完成,它应该复制所有数据。
使用 Azure Functions 连接到SQL Server
使用数据工厂连接到SQL Server
概述
本文档提供了在Microsoft Fabric 中设置数据管道以将数据从 增量共享 传输到SQL仓库的分步说明。此配置可实现 增量 Lave 源和SQL目标之间的无缝数据集成。
先决条件
- 具有适当权限的活动Microsoft Fabric 账户。
- 达美共享凭证。
- SQL仓库凭据。
- 访问 Fabric 中的数据流第 2 代。
步骤
访问数据流第 2 代
- 登录到Microsoft Fabur 账户。
- 导航到工作区。
- 从可用选项中选择"数据流第 2 代"。
配置数据源
- 点击"来自其他源的数据"以开始配置。
- 从"获取数据"屏幕执行以下操作:
- 找到标记为"选择数据源"的搜索栏。
- 在搜索字段中输入"增量共享"。
- 从结果中选择增量共享。
设置增量共享连接
- 出现提示时输入你的增量共享凭证。
- 确保准确填写所有必填字段。
- 如果可能,请验证连接。
- 点击"下一步"继续。
- 查看可用表的列表:
- 将显示你有权访问的所有表格。
- 选择所需的表格进行传输。
配置数据目标
- 点击"添加数据目标"。
- 选择"SQL仓库"作为你的目标。
- 输入SQL凭据:
- 服务器详细信息。
- 身份验证信息。
- 数据库规范。
- 验证连接设置。
完成和部署
- 查看所有配置。
- 点击"发布"以部署数据流。
- 等待确认消息。
验证
- 访问SQL仓库。
- 验证数据是否可用且结构是否正确。
- 运行测试查询以确保数据完整性。
故障排除
常见问题和解决方案:
- 连接失败:验证凭据和网络连接。
- 缺少表格:检查增量共享权限。
- 性能问题:查看资源分配和优化设置。
使用 Fabur 笔记本连接到SQL Server
概况
将Microsoft Fabric 中的数据工厂与增量共享配合使用,可实现共享增量表的无缝集成和处理,作为使用 Analytics 2.0 的分析工作流的一部分。增量共享是一种用于安全数据共享的开放协议,可允许跨组织协作而不会重复数据。
本指南将引导你完成在具有增量共享的 Fabric 中设置和使用数据工厂的步骤,利用笔记本处理数据并将数据导出到 Lakcore。
先决条件
- 分析 2.0 SPU
- 增量共享凭证:
- 访问数据提供商提供的增量共享凭证。
- 共享配置文件文件( config.share)包含:
- 端点URL (增量共享服务器URL)。
- 访问令牌(用于安全数据访问的不记名令牌)。
- 使用以下模板创建带有特定凭证的 Config.yaML 文件:
{
"shareCredentialsVersion": 1,
"endpoint": "your-delta-sharing-server-url",
"bearerToken": "your-master-token"
}
- Microsoft Fabric 环境:
- 具有活动订阅的Microsoft Fabric 租户账户。
- 启用结构的工作区。
- 包和脚本:
- 下载 fabric-lavehous 包。该目录应包括:
- ms_to_lackcore.py:笔记本代码。
- 自述文件.md:指示。
注意:你可以从公司级别Analytics工具下载压缩包(通过Analytics > 入门>连接选项> Azure )。
- 下载 fabric-lavehous 包。该目录应包括:
步骤
设置配置
- 创建配置文件文件并按以下结构定义配置
source_配置:
配置路径:路径/到/你的/增量共享凭证文件.share
表:#可选 - 留空以处理所有表格
- 表名称1
- 表名称2
target_配置:
lavecore_路径:路径/to/your/fabric/lackhous/Tables/ #Fabrik Lavecore 的路径
设置你的 Lakcore
- 打开你的Microsoft Fabur 工作区。
- 导航到你的 Lavecore 并点击打开笔记本,然后点击新建笔记本。
- 如果你不知道config.yaML#lackhous_路径中的值,可以从屏幕复制。
- 点击 "文件" 上的省略号,然后选择 "复制 ABFS 路径" : -using-fabri-notebooks" score。文件名="cipboard_e390331535300f7f89fd0a91c9a3avebe.png" scu="./cipboard_e390331535300f7f89fd0a91c9a3avebe.png" />
3。复制ms_to_lavecore.py的代码并粘贴到 notebook 窗口中(Pyspark iPhone):
下一步是将你自己的 Config.yaML 和 Config.share 上传到 Lakcore 的Resources文件夹中。你可以创建自己的目录或使用内置目录(已由Lagehous为资源创建):
下面的示例显示了 Config.yaML 文件的标准内置目录。
注意:确保在同一级别上传两个文件,并且对于属性 FIFA 路径:
4.检查笔记本的编号,第 170-175 行。
下面的示例显示了必要的项目变更:
配置路径= "./env/配置.yaML"
到
配置路径= "./内置/配置.yaML "
由于文件位于内置文件夹中而不是在自定义env中,因此请务必监控你自己的文件结构。你可以将它们上传到不
5.点击运行单元格:
验证
- 作业完成后,验证数据是否已成功复制到 Lakcore。
- 检查指定的表并确保数据与共享的增量表匹配。
- 等待作业完成,它应该复制所有数据。
连接到数据块
注意
此连接方法通常由数据专业人士使用。- 登录到 Databricks 环境。
- 导航到目录部分。
- 从顶部菜单中选择增量共享。
- 选择与我共享。
- 复制为你提供的共享标识符。

- 在 Procore 中,点击导航栏右上角区域的"账户和个人资料"图标。
- 点击我的个人资料设置。
- 点击分析标签页。
- 输入你的Databricks 共享标识符。
- 点击连接。
注意:将共享标识符添加到 Procore 系统后,Procore Databricks 连接将显示在 Cloud Drives 环境中的"提供商"下的"与我共享"标签页中。最多可能需要 24 小时才能看到数据。
- 当你的 Procore Databricks 连接在与我共享的标签页中可见时,选择 Procore 标识符并点击创建目录。
- 输入你喜欢的共享目录名称,然后点击创建。

- 你的共享目录和表格现在将显示在目录资源管理器中提供的名称下。

注意:如果你有任何问题或需要帮助,请联系 Procore 支持团队。
使用 Android 连接到 Snowplace
使用 Android 连接到Amazon S3
建立你自己的联系
连接到 大查询
使用 Exponam 连接到Microsoft Excel
概况
本指南提供了使用 Exponam.Connect 加载项将 Analytics 数据从 增量共享 直接导入Microsoft Excel 的分步说明。
使用此方法可以:
-
直接在Excel中访问你的 Procore 数据,而无需手动下载 CSV。
-
在导入前筛选和选择特定列,确保仅加载所需的数据。
-
处理否则可能会因速度太慢而无法处理的大型数据集。
先决条件
-
增量共享凭证。访问包含增量共享凭证的config.share 文件。
-
发牌:
-
Exponam.Connect免费:仅限导入 100 行数据。
-
Exponam.Connect Pro :导入更大的数据集(最多 100 万行以上)所需。
-
安装 Exponam 加载项
-
运行安装程序文件并按照屏幕提示进行操作。
-
安装完成后,启动Microsoft Excel并打开一个新的工作簿。
初始化增量共享连接
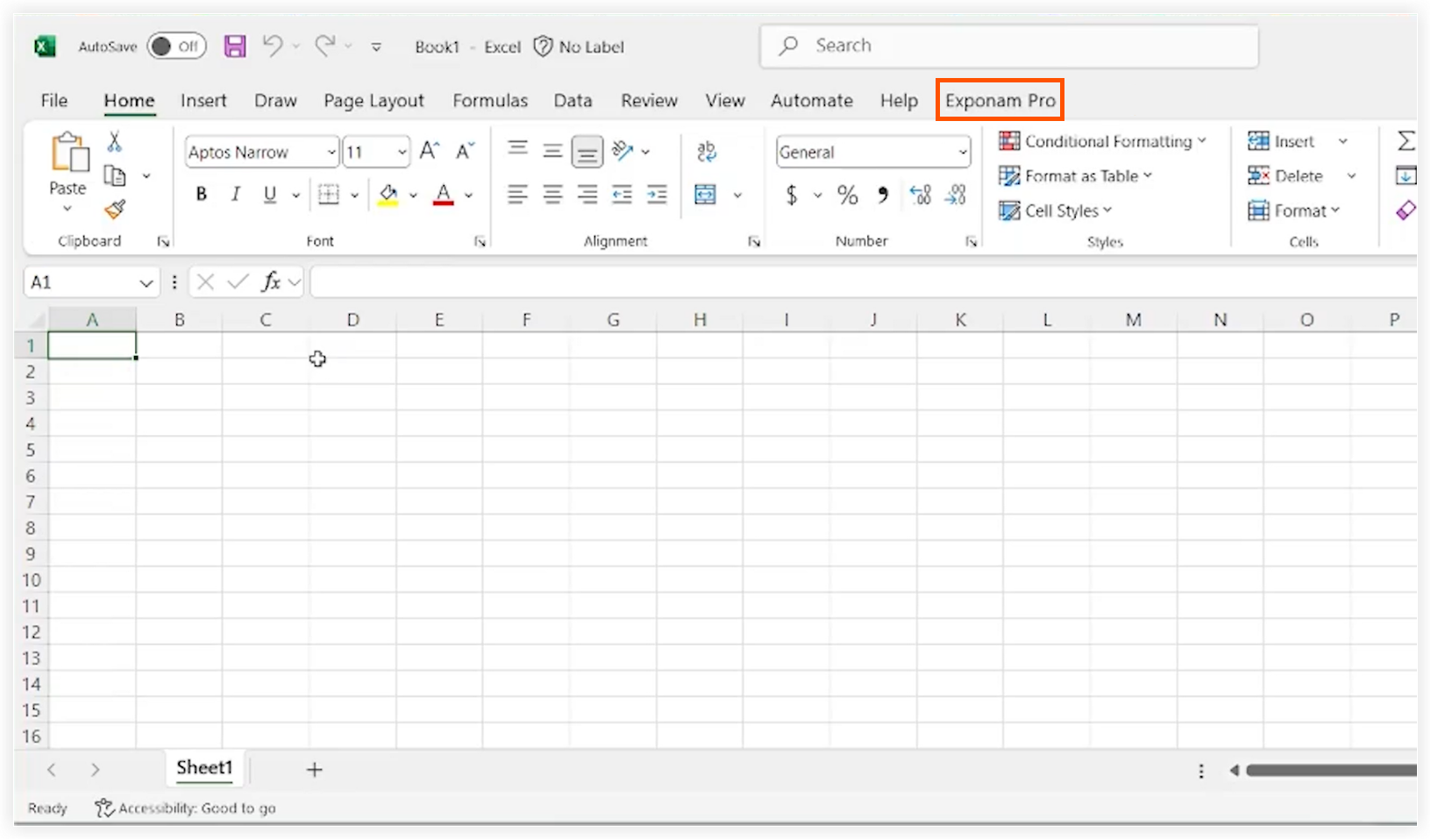
-
在Microsoft Excel中,导航到Exponam Pro标签页。
-
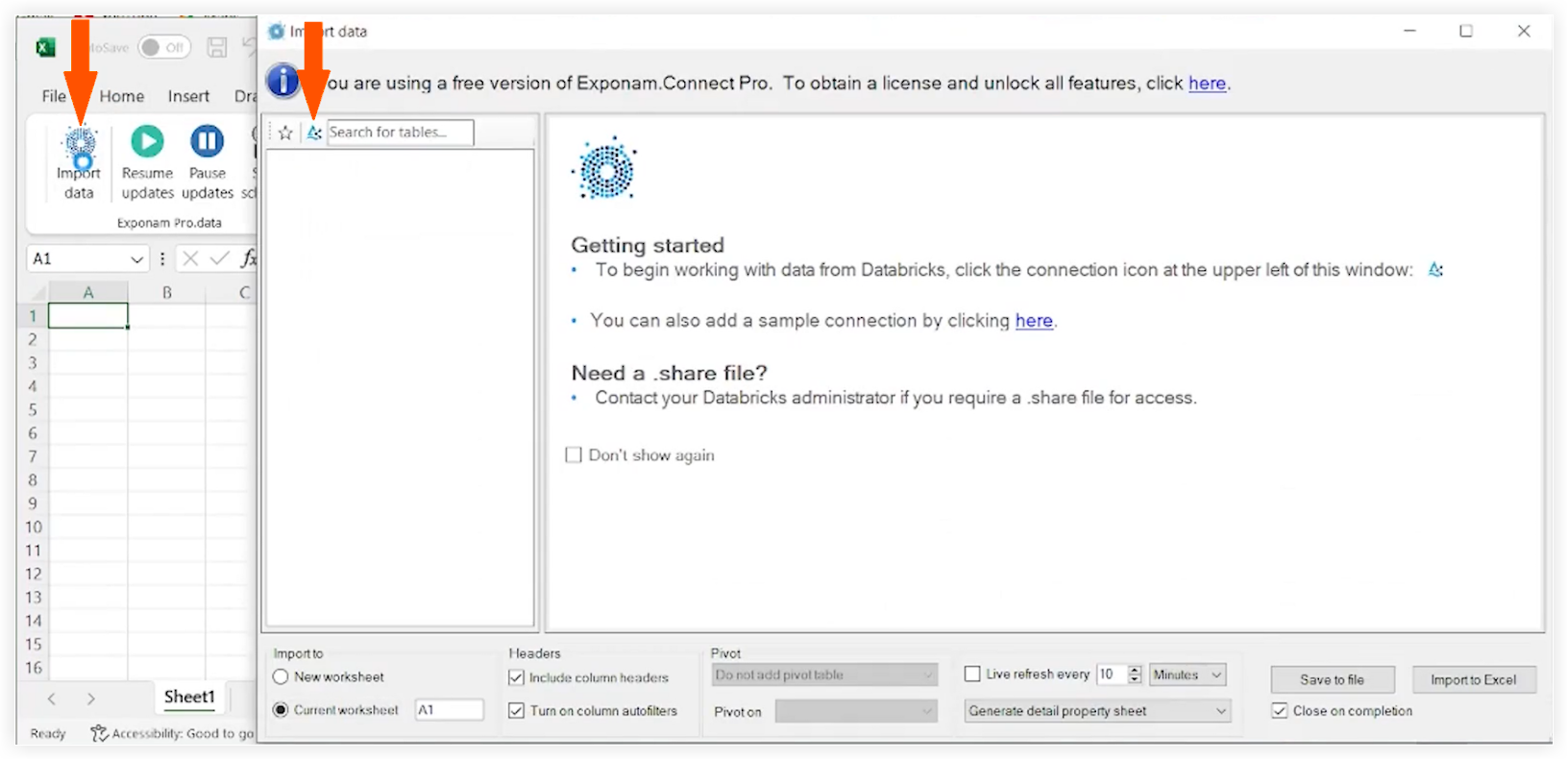
点击导入数据。
-
点击增量共享图标。
-
找到并选择 config.share 文件。
-
点击打开。
选择和筛选数据
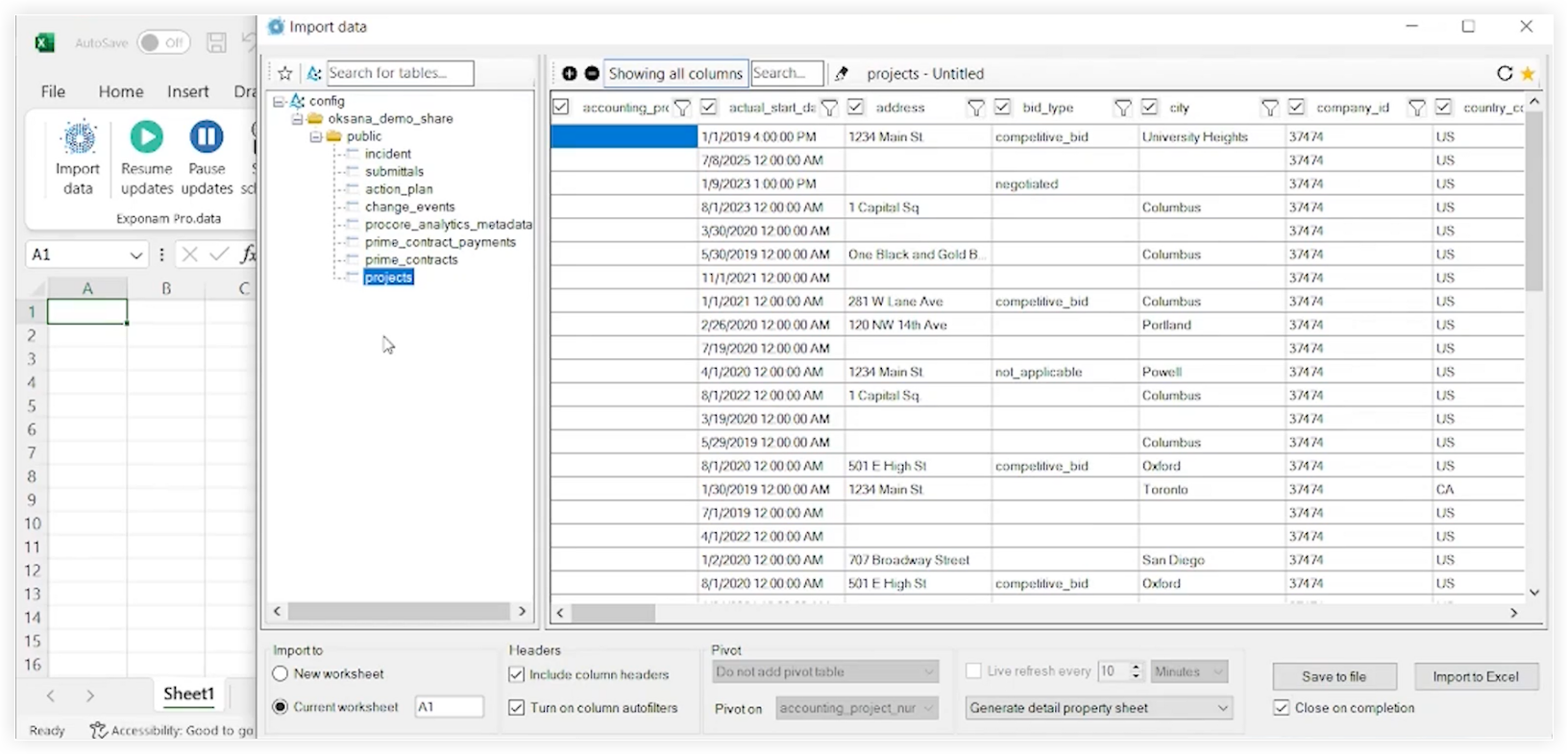
Exponam 界面现在将显示所有可用数据表的列表。
-
点击你要访问的表的名称。
-
在导入到Excel之前,使用 Exponam 界面优化你的数据。例如,你可以应用筛选器、选择特定列等。
导入到Excel
-
查看你的配置和行数。
注意:确保行数在你的许可证限制内。 -
点击导入到Excel 。
数据将填充到活动Excel工作表中。
验证
-
确保Excel中的列和行与你在 Exponam 窗口中选择的内容匹配。
-
检查数据类型(日期、货币等)的格式是否正确。
故障排除
-
缺少"Exponam Pro"标签页。确保安装成功并检查Excel "加载项"设置以确认其已启用。
-
连接错误。验证 config.share 文件是否仍然有效以及是否具有活动的互联网连接。
-
已达到行限制。如果仅显示 100 行,请在 Exponam 设置中检查许可证状态。